 I'm, the bookworm
I'm, the bookworm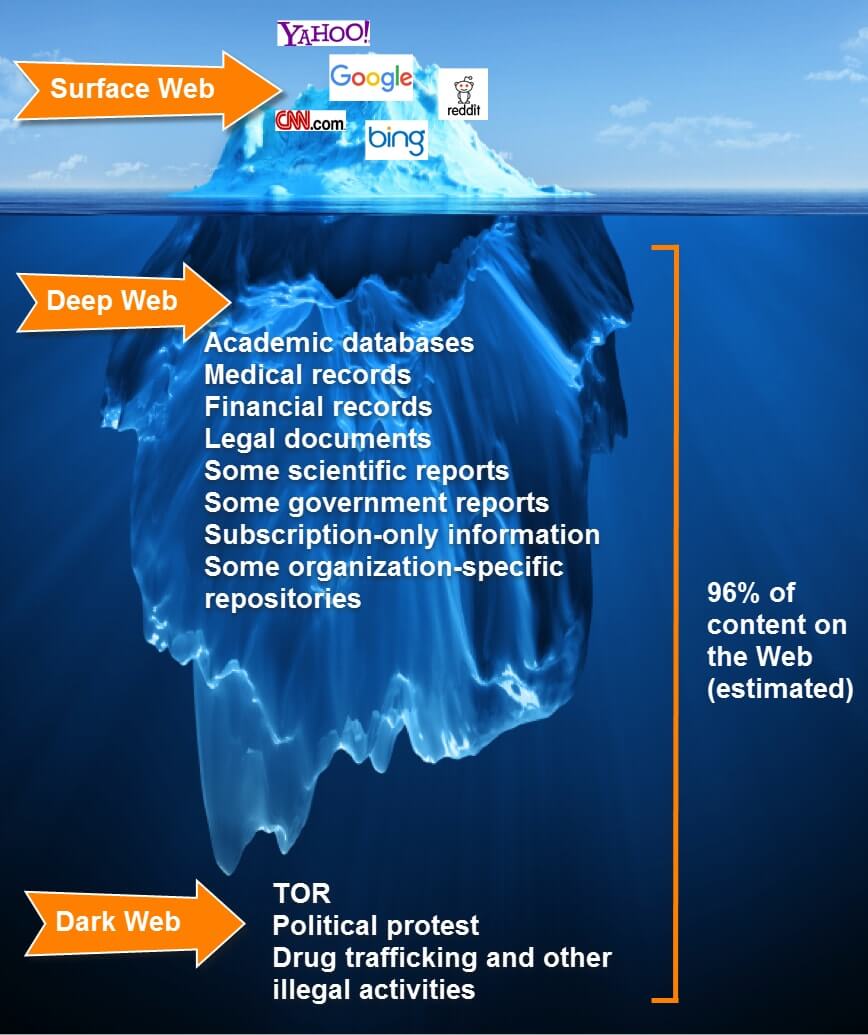 Számtalan, a deep webbel alap szinten foglalkozó írásban és előadáson találkozhatunk azzal a kijelentéssel, hogy a deep web méretét tekintve a hagyományos web több százszorosa. Amellett, hogy én ezzel kapcsolatban mindig szkeptikus voltam, olyat még nem láttam, ahol valaki ezt egy komoly forrásmegjelöléssel igazolta volna, így felvetődik több fontos kérdés. [UPDATE: forrás persze van, de az egy 2001-es, azaz laza 16 évvel ezelőtti, extrapolációs modellre alapozott kutatás.] A kérdés, hogy netes a kontextusban mit értünk egyáltalán információ alatt. Ugyanis teljesen mindegy, hogy ilyen-olyan akadémiai kutatások mekkorára becsülik a teljes deep web információtartalmát, abban az esetben, ha ezek gyakorlati szempontból nem érhetők el a deep web híres-hírhedt kvázi kereshetetlensége miatt, ha nincs olyan eszköz a kezünkbe, amin keresztül a számunkra szükséges információ gyorsan és hatékonyan kereshető, elérhető, akkor inkább hidden serviceket működtető szerverek adathordozóin lévő adatról helyes beszélni, nem pedig információról.
Számtalan, a deep webbel alap szinten foglalkozó írásban és előadáson találkozhatunk azzal a kijelentéssel, hogy a deep web méretét tekintve a hagyományos web több százszorosa. Amellett, hogy én ezzel kapcsolatban mindig szkeptikus voltam, olyat még nem láttam, ahol valaki ezt egy komoly forrásmegjelöléssel igazolta volna, így felvetődik több fontos kérdés. [UPDATE: forrás persze van, de az egy 2001-es, azaz laza 16 évvel ezelőtti, extrapolációs modellre alapozott kutatás.] A kérdés, hogy netes a kontextusban mit értünk egyáltalán információ alatt. Ugyanis teljesen mindegy, hogy ilyen-olyan akadémiai kutatások mekkorára becsülik a teljes deep web információtartalmát, abban az esetben, ha ezek gyakorlati szempontból nem érhetők el a deep web híres-hírhedt kvázi kereshetetlensége miatt, ha nincs olyan eszköz a kezünkbe, amin keresztül a számunkra szükséges információ gyorsan és hatékonyan kereshető, elérhető, akkor inkább hidden serviceket működtető szerverek adathordozóin lévő adatról helyes beszélni, nem pedig információról.
Azaz, hogy ne menjek messzire, ha valaki azzal kapcsolatban szeretne tájékozódni, hogy a legfrissebb kutatások szerint a TOR-on vagy a Freeneten lévő hivatkozások mekkora része döglött link, mennyi lehet azoknak az oldalaknak az aránya, amire konkrétan csak egy-két másik oldal mutat, a Google Scholaron keresztül vagy a SciHubon rogyásig talál ezzel kapcsolatban cikkeket, aztán az már a témában való jártasságán múlik, hogy azokat a cikkeket nézze meg, amire ténylegesen szüksége van, míg például a TOR-on sokszor relatív egyszerű tartalmak megtalálása is akadályokba ütközik. /*Azzal most ne kekeckedjünk, hogy a SciHub is hidden service végülis.*/
Azaz ha nagyon szemléletesek szeretnénk lenni, akkor azt is mondhatnánk, hogy egy hatalmas könyvtárban is csak az az adathalmaz tekinthető információnak, ami katalóguson keresztül kereshető, egyébként kvázi nem létezik.
Ráadásul a mai világban az információnak nem elég kereshetőnek lennie, közhelyesnek tűnik, de gyorsan és hatékonyan kereshetőnek is kell lennie olyan értelemben, hogy a nem kimondottan információkinyerésre szakosodott kutatónak, na meg úgy egyáltalán bárkinek ne kelljen túl sokat foglalkoznia a keresés mikéntjével, a kereső mégis adjon releváns találatokat. A digitális írástudás része kellene, hogy legyen a Google haladó operátorok ismerete, hogy mi az, amit éppen a piacvezető keresőmotorokkal kevésbé érdemes keresni, mit keressünk Shodannal, Google Scholarral, Duckduckgoval, azaz nem arról van szó, hogy egyáltalán ne kelljen értenie az átlag felhasználónak a kereséshez, de az elvárható, hogy ne kelljen nagyon trükköznie és agyalnia ahhoz, hogy releváns forrásokra találjon.
A gyorsaság és a hatékonyság mellett még kiemelném azt, amit én közel valós idejűségnek nevezek, azaz, hogy egy megjelent tartalom ne ezer év után kerüljön fel egy webes kereső indexébe, egy közösségi médiában, felkerülő, de a web felől nem látható tartalmat, így például egy Facebookon vagy VK-n megjelenő posztot a rendszer indexelje is, amilyen gyorsan csak tudja, hogy az mások számára kereshető legyen.
Ezeknek a feltételeknek a legnagyobb deep web hálózatok keresőinek egyike sem tesz eleget, azaz inkább adatot tárol, de nem információt, ebben pedig belátható időn belül nem is várható változás, hiszen egy hatékony keresőszolgáltatás működtetése erőforrásigényes, ennek megfelelően drága, jelen esetben túl drága ahhoz, hogy egy hatékony keresőszolgáltatást önkéntesekre támaszkodva, crowdfunding alapon építeni lehessen. Röviden, nem várható egy onionos google megjelenése.
Szó sincs róla, hogy a deep web értéket el akarnám bagatellizálni, csak a deep web ezen félreértett jellegére hívnám fel a figyelmet.
Adja magát a kérdés, hogy a nyílt-forrású információszerzésben milyen eszközként tekinthetünk a deep webes világra? A deep web számos esetben fontos forrás lehet, de ne legyenek illúzióink, egy olyan világban, ahol még az is hatalmas információs lábnyomokat maga után, aki nem vagy csak alig használ közösségi szolgáltatásokat, a weben, a web felől nem indexelt, de a közösségi szolgáltatásokban elérhető és más, hagyományos netes szolgáltatásokban rendszerint elérhetőek a számunkra fontos információk, valamint az azok közti relációk olyan mennyiségben, amennyire szükségünk van, még ez is bőven elég. Ráadásul úgy, hogy bizonyos tartalmakat a Bing-Google-Yahoo-szentháromság, de akár még a Yandex Search is szándékosan nem tesz kereshetővé, a közösségi weben sokszor még a jól megtervezett keresési technikákkal is falnak megyünk, lévén, hogy azokban kevésbé prioritás, hogy minden azonnal, mindenki számára kereshető legyen.
Hogy az utóbbi gondolat érthetőbb legyen: ha én a Facebookon kiteszem mondjuk egy általam kitalált eperpuding receptjét posztként és annak láthatóságát publikusra állítom, gyakorlatilag biztos lehetek benne, hogy az ismerőseim, valamint ismerőseim ismerősei számára a pudingrecept azonnal kereshető a Graph Search-ön keresztül. Adott például egy Kolumbiában élő felhasználó, akivel nincs közös ismerősöm, sosem váltottam vele üzenetet, úgymond semmilyen interakció nem volt köztünk, nem vagyunk semmilyen közös csoportban, ahogy még csak olyan oldal sincs, amit mindketten lájkolnánk és más nyelven használjuk a Facebookot és más nyelv van megadva azok közt a nyelvek közt, amiket a Settings alatt általunk értett nyelvekként jelöltünk meg. A Facebook keresője mögötti logika van olyan intelligens, hogy nem ész nélkül próbál mindent kétpofára felindexelni, majd az mindenki számára kereshetővé tenni. Előnyben részesíti azokat, akik valószínűleg az adott tartalomra kíváncsiak lesznek és számukra korábban válik kereshetővé egy-egy tartalom leggyorsabban, míg a képzeletbeli Kolumbiai felhasználó hiába keres a képzeletbeli posztra például úgy, hogy olyan eperpuding receptek leírását szeretné látni, amiket ebben a hónapban posztoltak, az én képzeletbeli posztom esetleg egyáltalán nem fog előtte megjelenni! Azaz ebben a kontextusban a netsemlegesség keresés szempontjából túl drága lenne és persze nincs is rá olyan szintű igény, ami indokolná, hogy ezen változtassanak, hiszen nem nyílt-forrású információszerzéssel foglalkozik a világ összes felhasználója.
Visszatérve a deep webre, nagyon meg lennék lepve, ha kiderülne, hogy egy átlagos use caseben - már ha egyáltalán létezik ilyen - a deep weben keresve valaki gyorsabban végezne egy teljes kutatással, mint a hagyományos weben keresztül. Természetesen más a helyzet, ha valaki tipikusan olyan ügyben folytat kutatást, amivel kapcsolatban a deep webről várható használható információ, ilyen például a fegyverkereskedelemmel, drogkereskedelemmel kapcsolatos információk, bérgyilkos-rendelő szolgáltatások, kiskorúak sérelmére elkövetett erőszakos bűncselekmények bizonyítékai, meg úgy általában olyan, ami minden államban tiltott, normális ember pedig nem szivesen lát a képernyőn.
Nemrég felröppent, hogy az ISIS saját közösségi szolgáltatást hozott létre, miután a mindenki által jól ismert webes óriások hangzatosan bejelentették, hogy fellépnek a radikalizálódó tartalmak és az azokat terítő felhasználók ellen - aminél nagyobb ostobaságot, mi több, bűnt nem is követhettek volna el, ahogy arról korábban beszéltem. Ami az ISIS közösségi szolgáltatását illeti, olyan, mint Columbo felesége, beszél róla mindenki, de alighanem még senki sem látta. Abban az esetben viszont, ha van ilyen, meg lennék lepődve rajta, teljes egészében vagy nagyrészt a deep webre támaszkodna egy bizonyos méret fölött, lévén, hogy a terrorista is ember. Ennek megfelelően életszerűtlen, hogy olyan egy ilyen feltételezett közösségi szolgáltatás egy - valljuk be - igencsak fapados, a 80-as évek netjének megoldásaira emlékeztető infrastruktúrát használjon. A terrorizmus amellett, hogy egy igencsak "réteg műfaj" avagy "underground", de nem annyira, hogy egy terrorizmussal foglalkozó csoportot túl nehezen lehessen elérni, túl bonyolult legyen a velük való kapcsolatfelvétel és kommunikáció, hiszen ez eleve a toborzást és a mai világban elvárt információáramlás sebességét tenné elégtelenné Dzsihád Dzsoni és csapata számára.
Több éves empirikus tapasztalat, hogy kimondottan OSINT téren a deep webes hálózatok egyáltalán nem kiugróan értékes források. Sem az OSINT-tel foglalkozó nyilvános anyagok, sem pedig a szürkezónába tartozó magánkiadások nem foglalkoznak a deep webbel különösebben nagy súllyal, márpedig ez nem az a diszciplína, ahol gyakoriak lennének a méltatlanul elhanyagolt források és technikák. Ahogy azt sincs okunk feltételezni, hogy a világ vezető hírszerző csúcsszerveinél valamiféle szent grálként tekintenének a hidden service-ekre, természetesen arról szó sincs, hogy nem kutatnák és ne foglalkoznának vele, számtalan példát lehetne hozni azzal kapcsolatban, amikor egy-egy bűncselekmény nyomozásának a deep webnek kiemelt szerepe vagy konkrétan fő terepe volt, de szó sincs róla, hogy például a szervezett bűnözés vagy a terrorizmus egyszerűen átköltözött volna mindenestől a deep webre. Holott első blikkre logikusan azt várnánk, hogy az ő esetükben aztán tényleg indokolt. Kevésbé nyakatekerten fogalmazva, ha mondjuk egy teljes drogkartell, amelyik nagytételben tolja pszichotróp szerekkel a bizniszt olyan információs közegbe költözik, ahol kevésbé utolérhető, ugyanakkor kevésbé kereshető is a hatóságok számára, világos, hogy nem csak a hatóságok számára lesz nehezebben elérhető, hanem az ügyfélköre számára szintén, amivel nyilván hátrányba kerül a másik drogkartellel szemben.
Persze, több esetben a deep web tipikus eszköze egy-egy bűnözői szolgáltatás igénybevételének, ha például valaki bérgyilkost vagy emberi szervet rendelne, de ehhez nem kell a deep webre menni. Hirtelen az a néhány évvel ezelőtti eset jutott eszembe, amikor egy embercsempész bandát kapcsoltak le, ahol konkrétan fejlődő országokból lehetett gyerekeket vásárolni, ekkor azt gondolnánk, hogy csak-csak figyelnek a diszkrécióra, ehhez képest annyira idióták voltak az ügyfelek és az embercsempészek egyaránt, hogy mindezt egy Facebook-csoportban beszélték meg. Ahogy az is eléggé erős volt, amikor az Egyesült Királyságban két idióta terrorista nyitott Twitter-csatornán kért ötleteket azzal kapcsolatban, hogy mikor és hol robbantson, mert azt hitték, hogy a twiteket csak a követőik látják.
Távoli asszociáció: jól ismert, hogy a szervezett bűnözés és a terrorizmus sokszor olyan virágnyelvet használ, ami miatt még akkor sem világos, hogy miről beszélnek, ha egyébként technikailag sikeresen lehallgatják őket. Ugyanakkor ha ez eszelősen bonyolult lenne egy ilyen nyelv, egyszerűen nem használnák. A deep webbel, mint információs tereppel hasonló a helyzet. Persze, van működő feketepiaca a drogoktól a szervcsempészeten keresztül a 0day szoftveres sebezhetőségekig már mindennek, ezek egyike sem lehet egy bizonyos fokúnál jobban eldugva, mivel ilyen esetben konkrétan senki vagy túl kevesen tudnák egyáltalán megtalálni.
Összefoglalva, amikor egy kutatásban a hidden servicek nem jutnak különösebb szerephez a nyílt forrású információszerzésben, nem azért van, mert akik végzik, nem lennének kompetensek a használatában, hanem azért, mert sok esetben egyáltalán nincs rá szükség. Nagyon sok esetben a bűnügyi nyomozásoknál is erről van szó, suta analógiaként említeném, hogy a büntetőeljárások többségében titkos adatszerzés és titkos információgyűjtés és hasonló varázslatok nélkül is sikeresek vagy éppen amikor a gyanusított nem hajlandó semmit mondani. Hasonlóan a nyílt forrású információszerzéshez, a bűnügyi nyomozás is akkor professzionális, ha minél ötletesebben és minél egyszerűbben van egészében megtervezve.
kép: Wikipedia

