 I'm, the bookworm
I'm, the bookworm Már korábban írtam róla, hogy a deep webbel kapcsolatban, főleg a méretével kapcsolatban micsoda zavar van a fejekben.
Már korábban írtam róla, hogy a deep webbel kapcsolatban, főleg a méretével kapcsolatban micsoda zavar van a fejekben.
Abba most nem megyek bele, hogy miért a nehezebben vagy valamilyen módon költségesebben elérhető információ élvez mindig előnyt, természeténél fogva miért lesz mindig értékesebb, mint a könnyen kitúrható, akit érdekel, nézzen után a "miért vonzó, ami ritka?" vagy hasonló kérdésnek az evolúciós pszichológia területén.
Ha felteszem a kérdést, hogy a legtöbb, kereshetetlennek hitt, hidden servicekben létező, értelmes tartalmat fedő link az alábbiak közül honnan kukázható ki, alighanem a legtöbben azoknak a beidegződéseknek megfelelően válaszolnának, amiket kulturálisan a felhasználóba klopfoltak a web általános felhasználói szokásai. Szóval honnan is?
1. sehogy, de tényleg!
2. Google-ben nem indexelt, alternatív keresőkkel elérhető motorok
3. nagy keresőkben nem indexelt, de surface weben lévő blackhat fórumok
4. a deep web belső keresőmotorjai
5. kőkeményen fizetős adattárházak
6. Facebook
Jó, jó, konkrétan a nagyon-nagyon nehezen kivájható információ kereshetőségével foglalkoztam az elmúlt pár hónapban, mert végülis azelőtt is csak más technikával, aztán a napokban szembesültem pár kínos ténnyel.
Az egyik, hogy amit kikutattam, már megtalálta más, igaz, nem pontosan azt, nem pontosan annyit, nem úgy, nem is olyan régen, de mégis.
A másik, hogy mindez szép és jó, viszont kérdés, hogy mennyire használható ténylegesen a recon fázisban, ha etikus hekkelésről, ehh bocsánat, szóval szoftvertesztelésről, na meg threat intelligenceről van szó. Amiben biztos vagyok, hogy a módszer univerzálisan használható, bármilyen irányú OSINT-vájárkodásról legyen is szó.
A harmadik dolog pedig egy tudományfilozófiai természetű kérdés. Azt kiméricskélték, hogy a teljes univerzum tömege 10 az 55-edik hatványon, mármint grammban. A Nagy-Fermat-sejtést bebizonyították, ugyan teljes egészében még senki sem olvasta el, leszámítva azt a figurát, aki a fél életét feltette rá és megfelelően belőtte, hogy hogyan lehetne a legjobban alkalmazni az automatikus /*gépi*/ tételbizonyítást a probléma megoldására, a párezer oldalas bizonyítás ma már nem is számít olyan nagynak (!!). Amikor az ökológus megpróbálja megállapítani, hogy mennyi verőköltő bodobács él konkrétan a Hortobágyi Nemzeti Parkban nemzeti parkban, akkor nyilván nem számolja meg az összeset, hanem alkalmaz egy kis trükköt, amiből aztán ki lehet matekozni, hogy négyzetkilométerenként mennyi, ennek megfelelően összesen mennyi. /*Ha most valaki úgy gondolná, hogy az extrapolációs módszerek mindig a legjobbak, nem feltétlenül, amúgy meg én sem tudom, mert nem vagyok sem ökológus, sem statisztikus.*/ Az eredeti témához visszatérve mi a nagy helyzet akkor, amikor tehát meg kell állapítani, hogy a legtöbb _értelmes_ információ ebben, abban vagy amabban a térben létezik? Jó esetben nem szúrtam el sem a mintavételezés módját, sem pedig a kiválasztott technikákat és a munkahipotézissel kapcsolatos előfeltevés sem zavart be nagyon. Viszont egy hipotézis állítása elfogadható-e tényként, ha konkrétan bizonyítani nem lehet, viszont minden, adott pillanatban rendelkezésre álló információ azt támasztja alá, hogy igen, tényleg az adott helyen van a legtöbb ilyen infó és semmi sem cáfolja azt érdemben?
A termodinamika 0. főtételét sem lehet bizonyítani olyan módon, mint a többi fizikai összefüggést, viszont feltétel nélkül elfogadjuk, mivel sosem találtunk még kivételt a természetben, ami ellentmondana nekik, a rá épülő modellek pedig működnek. /*elméleti fizikusok, szedjetek szét!*/
Lényeg, hogy az információ, na meg a kereshető információ mennyisége ha véges, akkor nyilván mérhető is. De kellően sok ahhoz, hogy ne lehessek benne 100+1%-ig biztos, hogy semmit sem csesztem el. A kutatás kezdetekor pedig a kérdésfeltevés nem is az volt, hogy "hol mennyi kilóra?", hanem az, hogy egy elfeledett módszer mennyire és hogyan használható, mik annak a korlátai, az pedig egy mellékes megfigyelés volt, hogy ott találjuk a legtöbb _értelmes_ deep webes hivatkozást, ahol ember nem gondolta volna.
Semmilyen természetfölötti izében' nem hiszek, de ma reggel komolyan arra gondoltam, hogy olyan, mintha valamilyen természetfölötti erő alakította volna úgy, hogy a tényleges, kereshető adat illetve információ megmaradjon, ha értelmes, a többit meg elnyelte volna egy neutroncsillag vagy fekete lyuk. Vagy csak ez a benyomásom! Ahogy a mainstreamben lehetett olvasni, hogy bizonyos országokban az emberek azt hiszik, hogy a Facebook maga az internet, az átlag felhasználó meg abban a tudatban él, hogy a web maga a teljes internet, az advanced user meg azt gondolja, hogy a web és a P2P hálózatok tartalma az internet, én most azt gondolom, hogy a teljes internet kiegészül egy olyan darabbal, amit kereshetetlennek hittek, viszont ez is csak illúzió, ami végülis abból adódik, mint bárki másnál: alapvetően azt hiszem létezőnek, amit látok.
Kicsit hasonló a jelenség ahhoz, hogy amikor valaki információt keres a neten, akkor nem is nagyon próbálkozik az anyanyelvén és az angolon kívül mással, annyira természetesnek veszi, hogy ami információ, az csak ilyen nyelvű lehet. Holott jól belőtt becslés szerint ami a webet illeti, annak csak 49%-a angol nyelvű, én ezt még kevesebbre saccolom, mert az interneten a nyelvek eloszlásával kapcsolatos kutatásokat angol nyelvterületen élő kutatók végezték, ami bejátszhatott abba, hogy végül milyen eredményt kaptak. Szóval nem lennék meglepve, ha még kisebb lenne az angol nyelvű tartalmak aránya, joggal feltételezhetjük, hogy akkor nem csak a weben, hanem a teljes neten is.
Tévedés lenne úgy gondolni, hogy az, ami fontos, idővel úgyis megjelenik angol, orosz vagy spanyol nyelven úgy, hogy az könnyen kereshető is, mert esetleg az adott doksi szerzője nem is foglalkozik vele, hogy amit leír, annak más nyelven is elérhetőnek kellene lennie. Ahol pedig remekül tetten érhető, hogy a keresőmotorok igenis diszkriminálnak, ha a Google/Bing/Yahoo-szenthátomsággal vagy éppenséggel a Yandex-szel keresünk valamit, az milyen tragikusan teljesít olyan nyelvek esetén, amik nem latin vagy cirill betűs írásrendszert használnak. Ennek pedig nem pusztán az az oka, hogy a nagy, jól ismert keresőmotorok fejlesztői in english, en español valamint на русском gondolkoznak, hanem az is, hogy a legnagyobb motorok milyen nyelveken kapják a bemenő adatok legnagyobb részét, ami teljesen világos, hogy kihat a kereső későbbi használhatóságára, éppen azért, mert nyilván egyik sem tisztán izomból megy, hanem hatékony szemantikus keresőeszközként való működésre tanítja önmagát.
Jól ismert, hogy vannak amolyan baráti jellegű nyelvpárok, amikre hatékonyan lehet normális fordítást végző algoritmust írni, megint más nyelvpárokra meg kevésbé, ami ráadásul sokszor nem függ még attól sem, hogy a két nyelv mekkora.
Eléggé gyorsan eljutottunk a nyelvészet egy izgalmas területéhez, a nyelv és kultúra izoláló hatásához, amiről annyit tudok, hogy létezik, a hatása pedig óriási, amúgy meg annyira értek hozzá, mint a harangöntéshez. Hogy szemléletes példát hozzak, ha behajítjuk a keresőbe, hogy
chocolate cake recipes
igencsak releváns találatokat hozunk, ezt akármilyen jól fordítjuk japánra vagy arabra, majd dobjuk be a keresőbe, ugyanaz a kereső már sokkal rosszabbul fog teljesíteni, holott itt egy totál egyszerű keresésről van szó, csokoládétortát meg készítenek arab és japán nyelvterületen is. A piacvezető keresőmotorokat persze annyira nem érdekli, hogy más nyelveken is legyenek nagyon hatékonyak, nem is érdekük, tömegigényt kell kiszolgálniuk. Ez még csak nem is a legjobb példa volt, mert a Google jól felzabálta a közelkeletet is az utóbbi néhány évben, már lassan a http://yoolki.com/, a http://www.eiktub.com/ és a http://www.yamli.com/ is csak amolyan jópofa érdekesség lesz lassan, de hogy kínai tartalmat zsigerből a http://www.baidu.com/ , a https://www.sogou.com/ avagy https://www.360.cn/ motorral fognak keresni többen globálisan nézve, az biztos.
Nem újdonság, elvben egy szorosan összedrótozott világban élünk, gyakorlatilag meg ugyanúgy jelentkezik egyfajta nyelvi és kulturális buborék effektus és naivitás lenne azt gondolni, hogy ez el fog tűnni csak úgy. Ugyanakkor jó tudni, hogy vannak olyan keresőeszközök, amik a hagyományos keresőszolgáltatásokkal összemérve szemantikus keresés terén sokkal butábbak, viszont hatékonyabbak ha kultúrafüggetlen keresésről van szó.
A nyelvi- és kulturális izoláció, mint a kutatást hátráltató tényező, már rég ismert. Abban meg aztán semmi meglepő, hogy mindez jelentkezett az interneten is. Hogy hogyan lehetne feloldani a jelenséget - és egyáltalán fel kell-e oldani? - persze nem tudom. Amit viszont igen, hogy mindenki jobban járna, ha a nyelvtechnológus nem lenne rá lusta, hogy megértse az etikus hekker, a szociológus és a pszichológus gondolkodásmódját, az etikus hekker szánna rá időt, hogy _hogyan__gondolkoznak_ a világ túloldalán, na meg mindezek összes permutációja. Nem csak a tudomány, úgy mindenestől járna jól vele, de a globális biztonsági kockázatok, informatikai biztonsági kockázatok vagy trendibben fogalmazva a globális kiberbiztonsági kockázatok kezelése is hatékonyabbá válna, márpedig ezek egyre inkább a klasszikus biztonsággal összefonódva léteznek, nem pedig amellett. Ki tudja? Legrosszabb esetben ennek elmulasztásával a civilizáció kihalását okozzuk - amit minő manír, éppen a nyelvhasználat megjelenése tett lehetővé.
Ha már ennyire elkanyarodtam az eredeti topiktól: vérprofi bugvadász és fejlesztő kollégák! Tegyétek a szivetekre a kezeteket és valljátok be, hogy nem is gondoltátok, hogy programozási nyelvek közt is vannak olyanok, amikben a teljes szintaxis nem a megszokott latin írásrendszert követik, de szóhasználatukban is hajaznak kicsit arra a kultúrára, amiben keletkeztek! Nem kevés ilyen van. Mindez valamit gyönyörű szépen megmutat, de előtte egy kis kitekintést kell tennem. Ahogy az Arrival c. Amy Adams filmben úgy kábé minden bevezető szintű nyelvészeti kurzuson felmerül több kérdés - meg biztos a kocsmában is - az pedig a nyelv és a tudat viszonya. Az univerzalizmus szerint a gondolkodás meghatározza a nyelvet, a nyelvek közt csak felszínes eltérések vannak. A determinizmus szerint az anyanyelv meghatározza a beszélő gondolkodását. A relativizmus szerint a jelentéstani kategóriák kihatnak a gondolkodásra, de nem határozzák azt meg teljesen. Minddel kapcsolatban pár remek és egyszerűen magyarázó példát találhatunk Trón Viktor és Kálmán László Bevezetés a nyelvtudományba c. könyvében:
Ma is sokan azt gondolják, hogy az egyes nyelvek szóhasználati, grammatikai különbségei egyértelműen a yelvek beszélőinek sajátságos gondolkodását tükrözik. Annyi bizonyos, hogy szoros összefüggés van aközött, hogy milyen kifejezések vannak egy nyelvben, és hogy milyen fogalmak, megkülönböztetések vannak a beszélők fejében. A szakembereknek is sok olyan szavuk van, amelyet mások nem használnak. Hiszen azokat a dolgokat szeretjük megnevezni tudni, amelyek fontosak az életünkben; ez nem túl meglepő állítás. A halászok sok halat ismernek és neveznek meg, napjaink számítógépes gurui szintén sok olyan fogalmat ismernek (és ezért nevet is adnak nekik), amelyet a közönséges halandó nem.
Nézzünk egy példát arra, hogy az egyes nyelvek milyen dolgok között tesznek különbséget. A francia parmi
és entre elöljárószót magyarul egyaránt között-nek kell mondani, jelentésbeli különbségüknek a magyarban nincs megfelelője:
(1)
A között két francia megfelelője
a.
Mon arbre est parmi les autres arbres.
az én . . . -m fa van között a többi fák
’Az én fám a többi fa között van’
b.
Jean est entre les deux arbres.
János van között a két fák
’János a két fa között van’
Tehát a parmi azt jelenti, hogy ’közülük az egyik’, míg az entre azt, hogy 'közöttük elhelyezkedő'. Vagy vegyük az álmosság különböző kifejezéseit:
(2)
Az álmosság két különböző kifejezése
J’ai sommeil.
nekem van álmosság
’Álmos vagyok’
Ezek a különbségek tényleg azt takarnák, hogy a francia és magyar beszélők másképp gondolkodnak a dolgok térbeli elhelyezkedésével, illetve az álmossággal kapcsolatban? Távolról sem. Az, hogy mindkét nyelvben ugyanúgy gondolkodnak, leginkább ott érhető tetten, hogy ugyanazon tényekből azonos következtetésekre jutnak.
valamint
Eleanor Rosch (?–) kísérletei bizonyították, hogy a dani nyelv beszélői, akik csupán két színnevet különböztetnek meg a nyelvükben, ugyanolyan teljesítményt nyújtanak a tizenegy ún. fokális szín azonosításában, mint azok, akiknek nyelvében mind a tizenegy színnév szerepel (a dani nyelvet mintegy 180 ezer pápua beszéli Új-Guinea nyugati részén). A nyelvi relativizmus még enyhébb változata viszont, miszerint a nyelvi kategorizáció hatással van az emlékezetre, és így közvetve kihat a gondolkodásra, számos kísérlet fényében valószínűnek tűnik.
/*kiemelés tőlem*/
Röviden azt is mondhatnám, hogy mondjuk a polinéziai kannibálok nem azért nem beszélnek határozott integrálról, mert nem tudnák mentálisan reprezentálni azt, hanem azért, mert nincs benne a kultúrájukban és kész, de ha benne lenne, tudnának róla beszélni.
Na de most hogyan kapcsolódnak ide a nem latin írásrendszerű programozási nyelvek? Hogy bizonyos alapkoncepciók egyeznek az olyan jól ismert nyelvekkel, amik akár a jól ismert procedurális vagy éppen funkcionális programozási nyelvekben ismertek.
kép: allthingslearning.wordpress.com
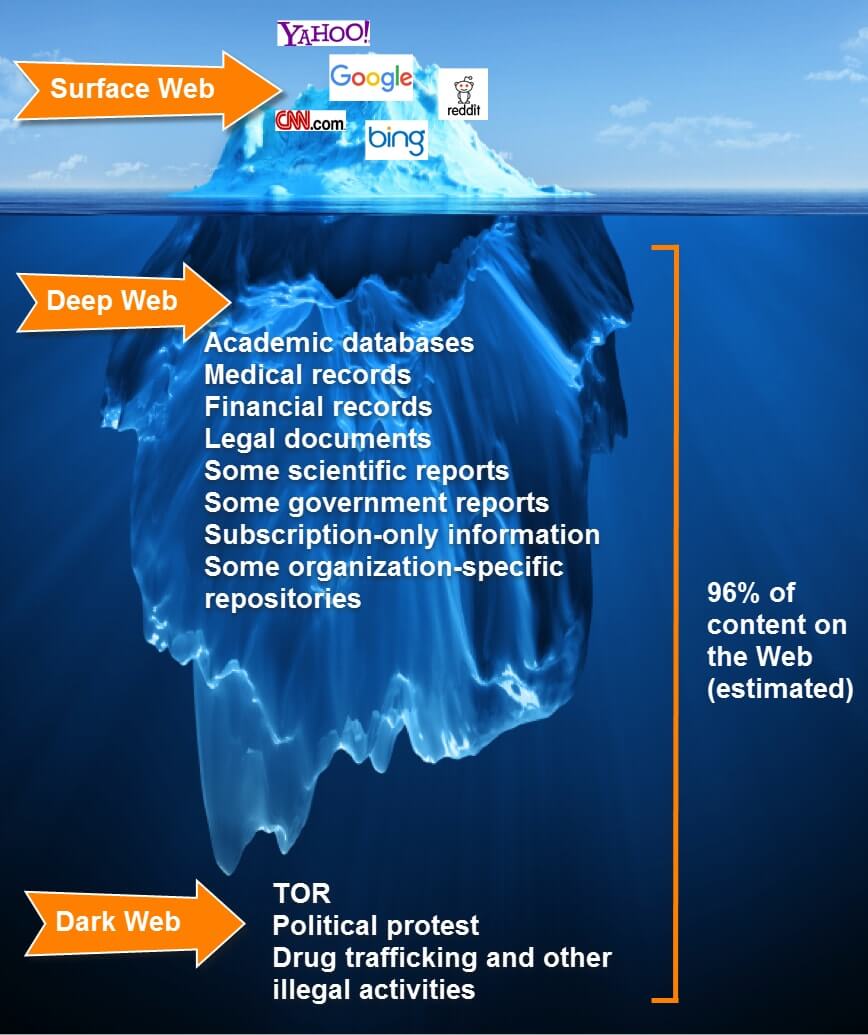 Számtalan, a
Számtalan, a